Achieving high parallelism with kafka

A software engineer, currently working at licious. Loves solving problems using software engineering.
In this post, we'll discuss consumer groups and how to achieve parallelism using them in Kafka. If you haven't read my previous blog posts about kafka, you will find them in the end.
Consumer Groups
As the name says, a consumer group is nothing but a group of consumers. Each consumer group is given a name. You can create as many consumer groups as you desire to listen to the same topic. Each consumer group can be at different offsets. That's the beauty of kafka. Here's how the consumer group works.
When you start a consumer, you give a name to it.
The consumer sends a request to the kafka broker by sending the consumer's name, topic, and partition number.
The kafka broker identifies the consumer by looking at its
__consumer_offsetstopic and returns the offset.The consumer gets the offset and sends another request to get the payload and continues with the processing of the message.
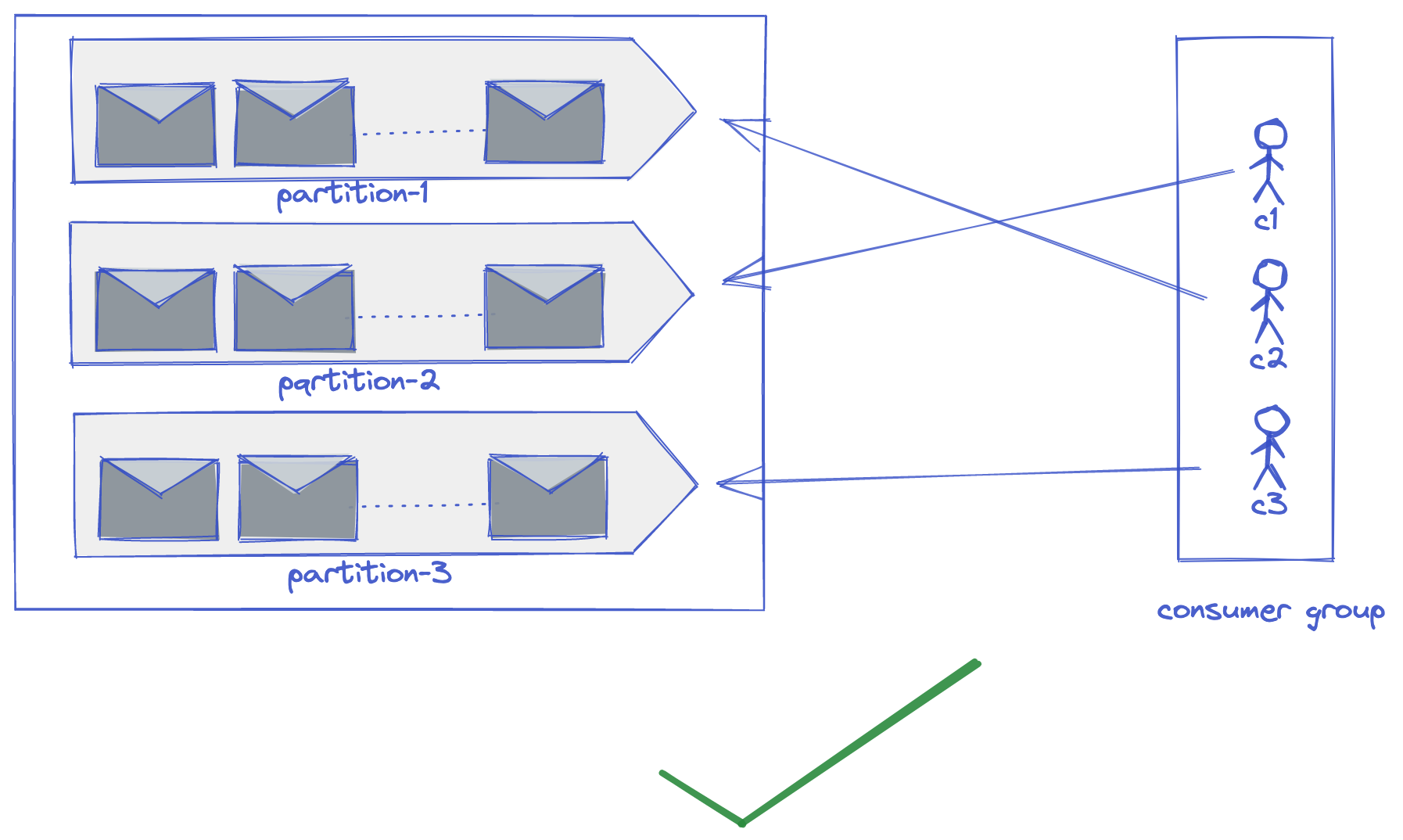
Relationship between consumer group and partitions
There is always either a one-to-one or one-to-many relationship between the consumers in a consumer group and partition. Meaning, one consumer can read one partition or one consumer can read many partitions. But, multiple consumers belonging to a consumer group cannot read the same partition. Can you guess why? It is a design decision taken by the kafka engineering team to implement message delivery guarantee semantics. There are 3 delivery guarantees any message queue system can provide.
At least once - has the possibility of duplicate events to be consumed/produced
At most once - has the possibility of losing events
Exactly once - the ideal scenario
Assume that kafka allows one partition to be consumed by many consumers in a consumer group. In order to deliver "exactly once" semantics it needs to maintain the state of each message at multiple consumer levels. This becomes convoluted and makes the system complex. To avoid that, the kafka team had taken the decision to restrict one partition to be consumed by only one consumer in a consumer group. This way, the kafka broker needs to maintain a single offset (integer) for a partition.
Achieving High Parallelism
Parallelism is the ability to do multiple tasks at once. High parallelism guarantees high consistency in high throughput systems. Let's take a practical example where parallelism is very important. Consider an aggregator service in an e-commerce system consuming events from different services. If the aggregator service is consuming events at a slower pace, it results in a huge lag in the consumers thus serving inconsistent information to the end-users. So, it is important to have high parallelism in the system to maintain high consistency.
How do we achieve it in kafka? The number of partitions in a kafka topic is directly proportional to the parallelism. Based on the use case, we need to define the number of partitions at the beginning. Though it is possible to modify the partitions later, it takes downtime to do that because kafka needs to rebalance the data among partitions and replicas. Also, it is important not to create too many partitions. We can calculate the partitions required based on the throughput of messages.
Additional Read
https://lokesh1729.com/posts/kafka-internals-learn-kafka-in-depth
https://lokesh1729.com/posts/kafka-internals-learn-kafka-in-depth-part-2


