A complete introduction to Kafka
As part of the Kafka internals series, in this post, I'll be writing a brief introduction to Kafka fundamentals, common jargon and basic architecture.

A software engineer, currently working at licious. Loves solving problems using software engineering.
Introduction
Kafka had gained huge popularity for the past few years. In a microservices architecture, it plays a pivotal role. It enables data to move from one service to another. I'm starting this series to help beginners understand Kafka in-depth. But, before we go in-depth, it is important to understand some basics. So, in this post, we'll learn the basics and eventually, we'll go in-depth.
Basics
"Kafka is a highly scalable, durable, fault-tolerant and distributed streaming platform." This is the definition we see from Kafka's official website. These jargons may frighten the newcomers. Let's learn the meaning of these first.
highly scalable: If the incoming messages of your Kafka are increasing, you can scale your system by adding more brokers to the cluster. You can scale it horizontally by adding more machines or vertically by adding more disk space.
durable: Durability is the ability to last longer. The messages sent to Kafka topic are persisted in the disk. They will not be deleted unless you configure them to delete.
fault-tolerant: First of all, fault-tolerant means the ability of the system to operate when one or more nodes are failed. In a Kafka cluster, even if a broker is down, the system still operates because of the replication. We'll learn about this in further posts.
distributed streaming platform: A stream is a continuous flow. In Kafka, producers will produce messages and consumers will consume. This stream never stops. That's why we call Kafka a streaming platform.
In a nutshell, Kafka works on the traditional client-server architecture. The server is Kafka, the producer (the one who sends data) and the consumer (the one who receives data) are the clients. The communication between client and server happens via customized high-performance TCP protocol implemented by the Kafka team. There are many client libraries available for most programming languages.
Events
An event describes something that happened. For example, in an e-commerce system, examples of events can be "an order is created", "an item is added to cart", "an order is delivered". In Kafka, we read or write data in form of events. An example of ORDER_CREATED event data looks like this. We can send this data in XML, JSON or Avro.
{
"order_id": "abcd-1234",
"order_amount": "50.00",
"created_by": "lokesh",
"created_on": "2022-02-09T22:02:00Z"
}
Basic Architecture
A producer is an entity that "sends" the data to Kafka. A consumer is an entity that "consumes" the data from Kafka. In Kafka, both these entities are loosely coupled. It means, the producer just produces irrespective of the consumer's existence. Similarly, the consumer's responsibility is to consume data from Kafka without depending on producers.
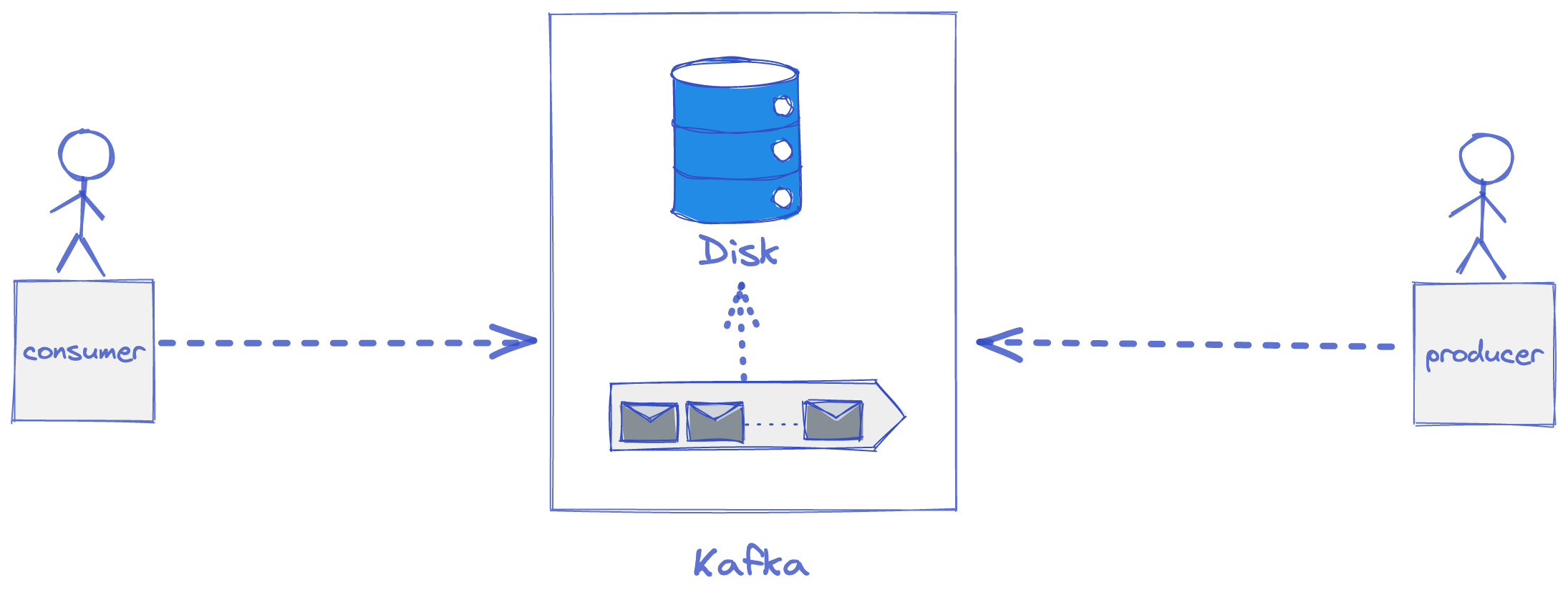
Topics & Partitions
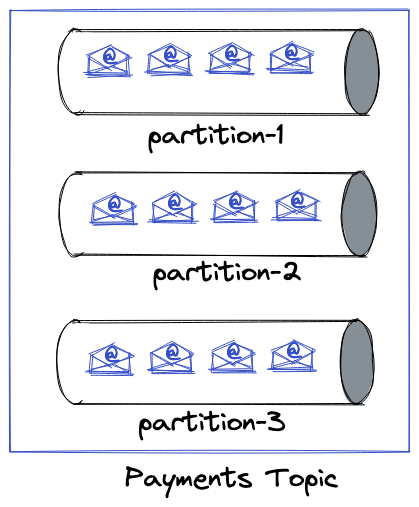
Events are categorized into topics. A topic contains related information. When designing data pipelines, topics are created based on semantics. Every topic has a meaning and purpose. For example, "payments" is a topic where payment-related events are received. Each topic is divided into multiple partitions. The topic is a logical entity in Kafka which means it doesn't exist physically whereas partitions do. When you create a topic with 'n' partitions, here's what happens under the hood.
- Kafka creates 'n' number of folders with names
topic-1,topic-2...topic-n. - In each folder, there will be files where the events are stored.
We'll go to the internal in coming posts. Now, coming to partitions, it is the smallest storage unit and an append-only data structure where the events are appended to the end. Partitions allow users to get parallelism. More the number of partitions, the higher the parallelism.
Partition Key
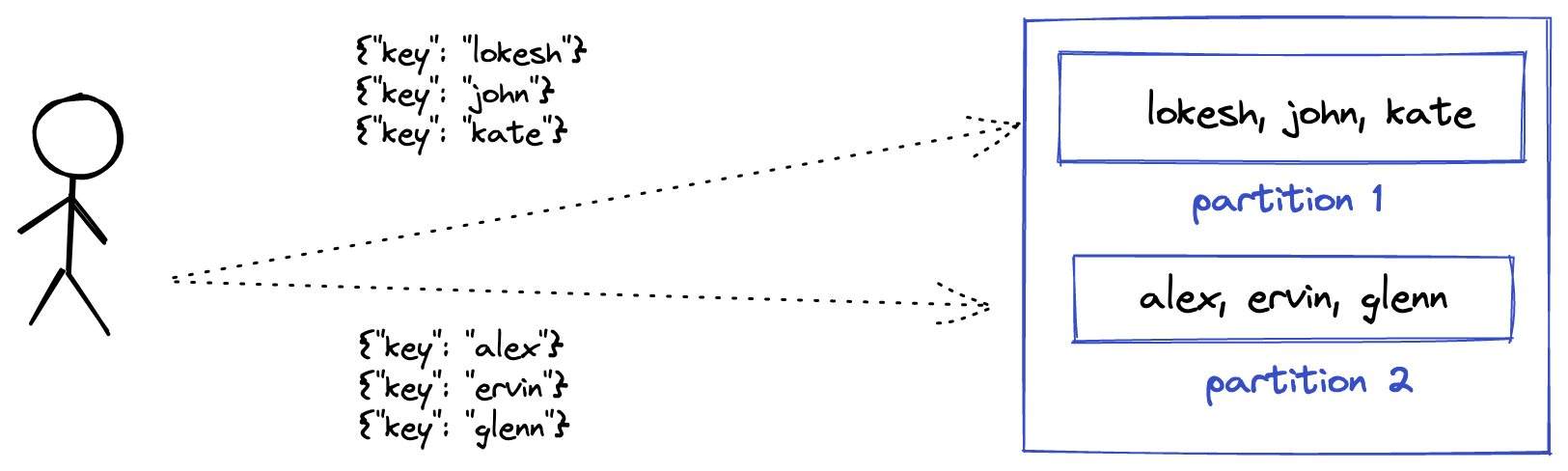
When the producers send messages to the Kafka broker, in which partition they will go? Well, if no partition key was sent, they'll go to a random partition. What is a partition key? it is an optional parameter when sent, Kafka makes sure that the messages with the same partition key are written into the same partition. Let's Illustrate it with the below image. Messages with partition key "lokesh, john & kate" are sent to partition 1. Same with the other keys. Under the hood, Kafka computes the hash of the partition key and applies modulo with the total partitions to get the partition. Partition key solves some use-cases where you need to aggregate messages based on the partition key.
How do consumers work?
When you start a consumer, here's what happens.
- We specify Kafka bootstrap URL (or zookeeper URL when provided Kafka brokers will be discovered automatically) to the consumer.
- The consumer opens a TCP connection with the broker and registers itself.
- The consumer asks the broker where it was and the broker returns the offset. The Kafka broker maintains consumer offsets in a separate topic called
__consumer_offsets. - The consumer keeps on polling continuously and starts consuming messages from the offset.
- The consumer completes the work and commits the offset back to the broker.
- The consumer moves to the next message and the process continues.
If your consumer takes more time to process each message, then you can change the configuration max.poll.interval.ms to a higher value. By default, it is set to 5 minutes. You can also tune max.poll.records which specifies the maximum records the consumer can fetch in a single poll call.
Offset
In computer science, the definition of offset from Wikipedia is as below. It's the same in the context of Kafka. It tells the message position.
Offset is an integer indicating the distance (displacement) between the beginning of the object and a given element or point, presumably within the same object.
Consumer Groups
As the name says, a consumer group is nothing but a group of consumers. Each consumer group is given a name. You can have as many consumer groups as you want. When you start a consumer group, it'll be registered with the Kafka broker which means all the consumers in that group will also be registered.
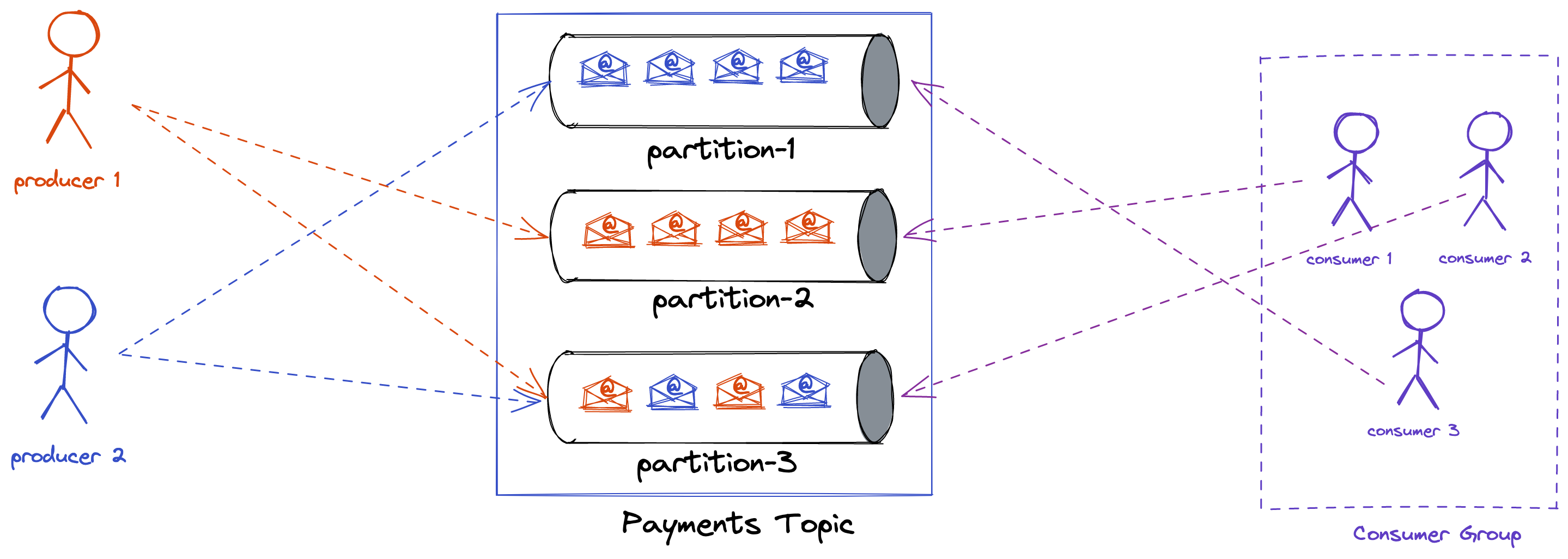
Comparision with traditional pub-sub systems.
Also, If you are familiar with traditional pub-sub messaging systems like rabbitmq, you may find a few differences.
The messages are deleted from rabbitmq once consumed. But, in Kafka, they are not deleted. They are persisted in the disk. This characteristic enables Kafka to act as a streaming platform.
In pub-sub systems, you cannot have multiple services to consume the same data because the messages are deleted after being consumed by one consumer. Whereas in Kafka, you can have multiple services to consume. This opens the door to a lot of opportunities such as Kafka streams, Kafka connect. We'll discuss these at the end of the series.
You can read more about the differences here


