Kafka Internals - Learn kafka in-depth (Part-2)
In my previous post, we learned about the basics of kafka. In this post, let's deep dive into the internals of kafka. How it is designed in such a way

A software engineer, currently working at licious. Loves solving problems using software engineering.
Introduction
In my previous blog post, we learned the basics of kafka and covered vital concepts. If you haven't read it, it is a prerequisite, please read it. In this blog post, we will deep dive into the internals of kafka and learn how kafka works under the hood. At the end of the blog post, your perspective about kafka will change so that you feel kafka is not complex as you think.
Basic Setup
Let's get started by installing kafka. Download the latest Kafka release and extract it. Open a terminal and start kafka and zookeeper.
$ cd $HOME
$ tar -xzf kafka_<version>.tgz
$ cd kafka_<version>
$ bin/zookeeper-server-start.sh config/zookeeper.properties
# open another terminal session and start kafka
$ bin/kafka-server-start.sh config/server.properties
Let's create a topic in a new terminal tab.
# Open another terminal and create a topic.
$ bin/kafka-topics.sh --create --topic payments --partitions 10 --replication-factor 1 \
--bootstrap-server localhost:9092
If you are wondering how the above command is constructed with those arguments, it's very simple. Just do,
bin/kafka-topics.sh --helpyou will see all the arguments with descriptions. It's the same case with all the shell utilities present inbinfolder.
Now let's see what happens under the hood.
Go to /tmp/kafka-logs directory and do ls we will see the below result.
cleaner-offset-checkpoint payments-0 payments-3 payments-6 payments-9
log-start-offset-checkpoint payments-1 payments-4 payments-7 recovery-point-offset-checkpoint
meta.properties payments-2 payments-5 payments-8 replication-offset-checkpoint
/tmp/kafka-logsis the default directory where kafka stores the data. We can configure it to a different directory inconfig/server.propertiesfor kafka andconfig/zookeeper.propertiesfor zookeeper.
recovery-point-offset-checkpoint
This file is used internally by the kafka broker to track the number of logs that are flushed to the disk. The format of the file is like this.
<version>
<total entries>
<topic name> <partition> offset
replication-offset-checkpoint
This file is used internally by the kafka broker to track the number of logs that are replicated to all the brokers in the cluster. The format of this file is the same as the recovery-point-offset-checkpoint file mentioned above.
topic & partitions
As we see from the above result, payments-0, payments-1 .... payments-10 are the partitions that are nothing but the directories in the filesystem. As I highlighted in my previous blog post, the topic is a logical concept in kafka. It does not exist physically, only partitions do. A topic is a logical grouping of all partitions.
Producer
Now, let's produce some messages to the topic using the below command.
$ cd $HOME/kafka
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic payments
> hello
> world
> hello world
> hey there!
We produced four messages on the topic. Let's see how they are stored in the filesystem. It's hard to find out to which partition a message went because kafka uses a round-robin algorithm to distribute the data to the partitions. The simple way is to find the size of all partitions (directories) and pick the largest ones.
$ cd /tmp/kafka-logs
$ du -hs *
8.0K payments-0
8.0K payments-1
12K payments-2
8.0K payments-3
12K payments-4
8.0K payments-5
8.0K payments-6
12K payments-7
8.0K payments-8
12K payments-9
As we see from the above snippet, our messages went to partitions 2, 4, 7 & 9. Let's see what's inside each of the partitions.
$ ls payments-7
00000000000000000000.index 00000000000000000000.log
00000000000000000000.timeindex leader-epoch-checkpoint
partition.metadata
$ cat 00000000000000000000.log
=
��Mr���Mr����������������
world%
$ cat partition.metadata
version: 0
topic_id: tbuB6k_uRsuEE03FsechjA
$ cat leader-epoch-checkpoint
0
1
0 0
$ cat 00000000000000000000.index
$ cat 00000000000000000000.timeindex
Partition Metadata
partition.metadata file contains a version and a topic_id. This topic id is the same for all the partitions.
Log file
This is where the data written by the producers are stored in a binary format. Let's try to view the contents of these files using command-line tools provided by kafka.
$ bin/kafka-dump-log.sh --files data/kafka/payments-7/00000000000000000000.log,data/kafka/payments-7/00000000000000000000.index --print-data-log
Dumping data/kafka/payments-7/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0
CreateTime: 1672041637310 size: 73 magic: 2 compresscodec: none crc: 456919687 isvalid: true | offset: 0
CreateTime: 1672041637310 keySize: -1 valueSize: 5 sequence: -1 headerKeys: [] payload: world
The explanation of the above output is self-explanatory except for a few properties. payload is the actual data that was pushed to kafka. offset tells how far the current message is from the zero indexes. producerId and produerEpoch are used in delivery guarantee semantics. We will discuss them in later blog posts. We will learn about .index and .timeindex files below.
Partition Key
We learned that kafka distributes data in a round-robin fashion to the partitions. But, what if we want to send data grouped by a key? that's where the partition key comes in. When we send data along with a partition key, kafka puts them in a single partition. How does kafka find the partition key? it computes using hash(partition_key) % number_of_partitions. If no partition key is present, then it uses a round-robin algorithm.
We may wonder, what is the use-case of a partition key? Kafka guarantees the ordering of messages only at a partition level, not at a topic level. The application of the partition key is to ensure the ordering of the messages across all partitions.
Let's see how this works under the hood. Let's produce some messages.
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic payments --property parse.key=true --property key.separator=\|
> lokesh1729|{"message": "lokesh1729 : order placed"}
> lokesh1729|{"message": "lokeh1729 : logged in"}
> lokesh1729|{"message": "lokesh1729 : logged out"}
> lokesh1729|{"message": "lokesh1729 : payment success"}
parse.keytells kafka to parse the key by the separator. By defaultkey.separatoris set to tab, we are overriding to pipe.
Let's look at the data using the same kafka-dump-log command. We need to find the partition by executing the command in all 10 partitions because we don't know to which partition it went.
$ $ bin/kafka-dump-log.sh --files data/kafka/payments-7/00000000000000000000.log,data/kafka/payments-7/00000000000000000000.index --print-data-log
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0
isTransactional: false isControl: false position: 147 CreateTime: 1672057287522 size: 118 magic: 2 compresscodec: none crc: 2961270358
isvalid: true | offset: 2 CreateTime: 1672057287522 keySize: 10 valueSize: 40 sequence: -1 headerKeys: [] key: lokesh1729
payload: {"message": "lokesh1729 : order placed"}
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0
isTransactional: false isControl: false position: 265 CreateTime: 1672057301944 size: 114 magic: 2 compresscodec: none crc: 204260463
isvalid: true | offset: 3 CreateTime: 1672057301944 keySize: 10 valueSize: 36 sequence: -1 headerKeys: [] key: lokesh1729
payload: {"message": "lokeh1729 : logged in"}
baseOffset: 4 lastOffset: 4 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0
isTransactional: false isControl: false position: 379 CreateTime: 1672057311110 size: 116 magic: 2 compresscodec: none crc: 419761401
isvalid: true | offset: 4 CreateTime: 1672057311110 keySize: 10 valueSize: 38 sequence: -1 headerKeys: [] key: lokesh1729 payload: {"message": "lokesh1729 : logged out"}
baseOffset: 5 lastOffset: 5 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0
isTransactional: false isControl: false position: 495 CreateTime: 1672057327354 size: 121 magic: 2 compresscodec: none crc: 177029556
isvalid: true | offset: 5 CreateTime: 1672057327354 keySize: 10 valueSize: 43 sequence: -1 headerKeys: [] key: lokesh1729 payload: {"message": "lokesh1729 : payment success"}
As we see from the above log, all the messages with key lokesh1729 went to the same partition i.e. partition 7.
Index and Timeindex files
Let's produce more messages with this script and dump the data using the above command.
$ bin/kafka-dump-log.sh --files data/kafka/payments-8/00000000000000000000.log,data/kafka/payments-8/00000000000000000000.index --print-data-log
Dumping data/kafka/payments-8/00000000000000000000.index
offset: 33 position: 4482
offset: 68 position: 9213
offset: 100 position: 13572
offset: 142 position: 18800
offset: 175 position: 23042
offset: 214 position: 27777
offset: 248 position: 32165
offset: 279 position: 36665
offset: 313 position: 40872
offset: 344 position: 45005
offset: 389 position: 49849
offset: 422 position: 54287
offset: 448 position: 58402
offset: 485 position: 62533
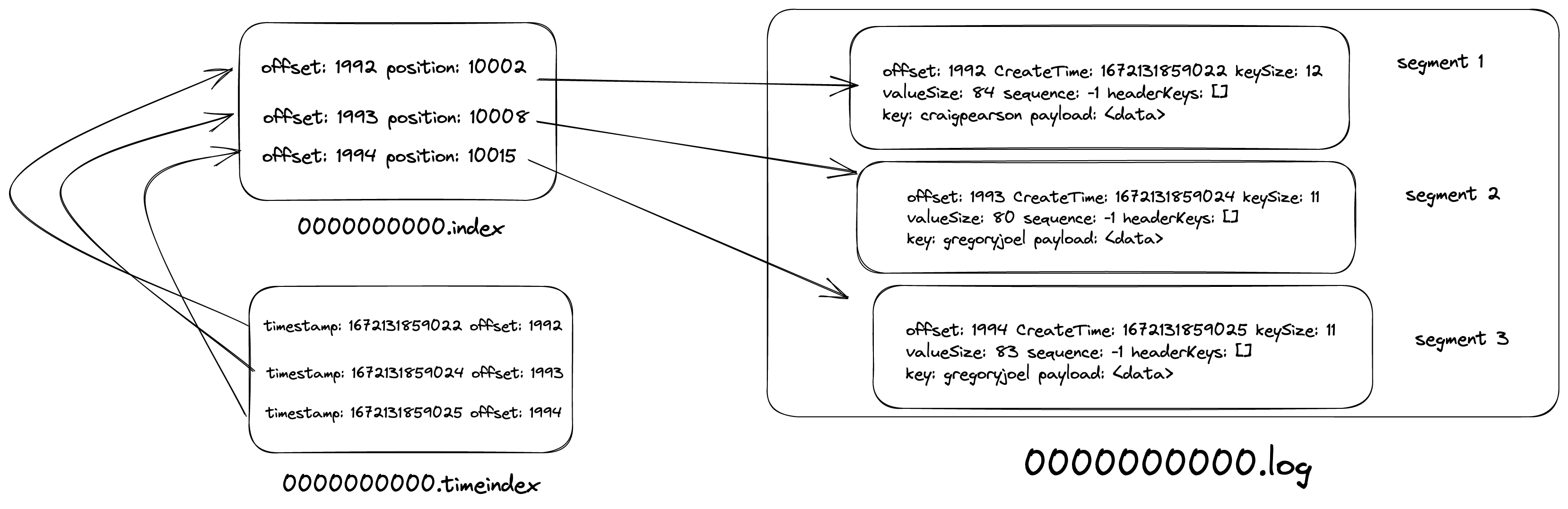
As we see from the above output, the index file stores the offset and its position of it in the .log file. Why is it needed? We know that consumers process messages sequentially. When a consumer asks for a message, kafka needs to fetch it from the log i.e. it needs to perform a disk I/O. Imagine, kafka reading each log file line by line to find an offset. It takes O(n) (where n is the number of lines in the file) time and latency of disk I/O. It will become a bottleneck when the log files are of gigabytes size. So, to optimize it, kafka stores the offset to position mapping in the .index file so that if a consumer asks for any arbitrary offset it simply does a binary search on the .index file in the O(log n) time and goes to the .log file and performs the binary search again.
Let's take an example, say a consumer is reading 190th offset. Firstly, the kafka broker reads the index file (refer to the above log) and performs a binary search, and either finds the exact offset or the closest to it. In this case, it finds offset as 175 and its position as 23042. Then, it goes to the .log file and performs the binary search again given the fact that the .log the file is an append-only data structure stored in ascending order of offsets.
Now, let's look at the .timeindex file. Let's dump the file using the below command.
$ bin/kafka-dump-log.sh --files data/kafka/payments-8/00000000000000000000.timeindex --print-data-log
Dumping data/kafka/payments-8/00000000000000000000.timeindex
timestamp: 1672131856604 offset: 33
timestamp: 1672131856661 offset: 68
timestamp: 1672131856701 offset: 100
timestamp: 1672131856738 offset: 142
timestamp: 1672131856772 offset: 175
timestamp: 1672131856816 offset: 213
timestamp: 1672131856862 offset: 247
timestamp: 1672131856901 offset: 279
timestamp: 1672131856930 offset: 312
timestamp: 1672131856981 offset: 344
timestamp: 1672131857029 offset: 388
timestamp: 1672131857076 offset: 419
timestamp: 1672131857102 offset: 448
timestamp: 1672131857147 offset: 484
timestamp: 1672131857185 offset: 517
timestamp: 1672131857239 offset: 547
As we see from the above result, .timeindex the file stores the mapping between the epoch timestamp and the offset in the .index file. When the consumer wants to replay the event based on the timestamp, kafka first finds the offset by doing a binary search in the .timeindex file, find the offset, and finds the position by doing a binary search on the .index file.
Consumer
Let's start the consumer using the below command
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic payments --group payments-consumer --from-beginning
{"message": "lokesh1729 : order placed"}
{"message": "lokeh1729 : logged in"}
{"message": "lokesh1729 : logged out"}
{"message": "lokesh1729 : payment success"}
Note that
--from-beginningargument is used to read from the start. If not used, the consumer reads the latest messages i.e. messages produced after the consumer is started.
Now, let's take a look at the filesystem. We can observe that there will be new folders created with the name __consumer_offsets-0, __consumer_offsets-1 .... __consumer_offsets-49. Kafka stores the state of each consumer offset in a topic called __consumer_offsets with a default partition size of 50. If we look at what's inside the folder, the same files will be present as in the payments topic we have seen above.
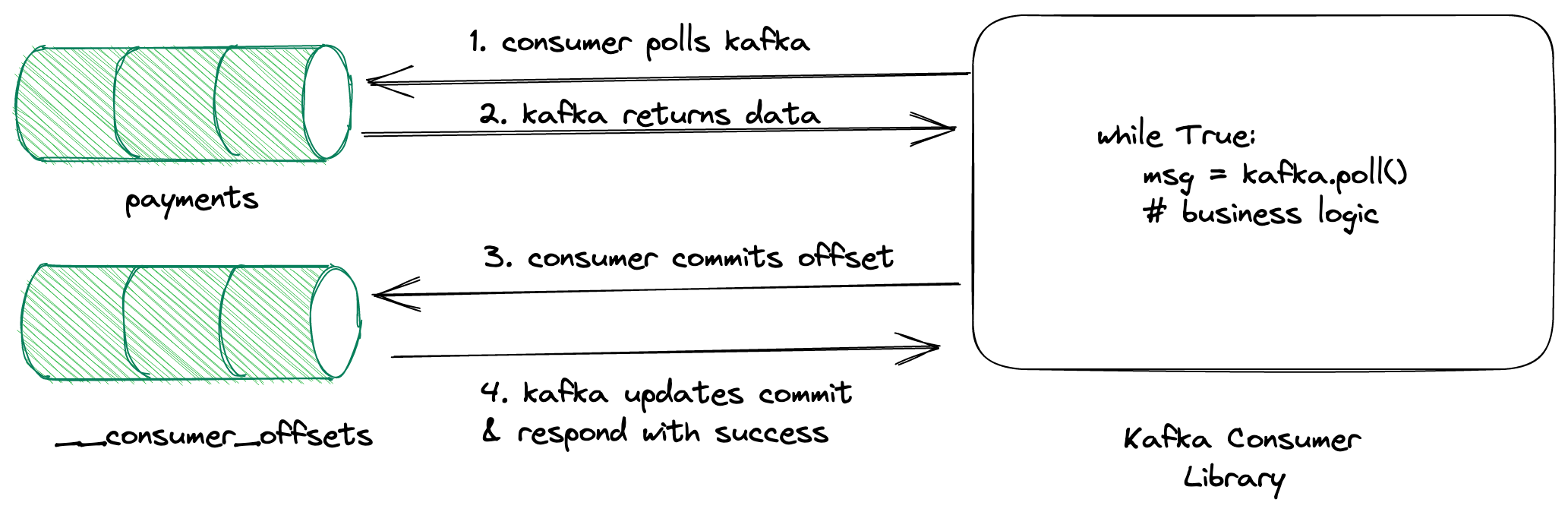
As we see from the above image, the consumer polls for the records and commits the offset whenever it's done processing. Kafka is flexible such that we can configure how many records to fetch in a single poll, auto-committing interval, etc... We will discuss all these configurations in a separate blog post.
When a consumer is committing the offset, it sends the topic name, partition & offset information. Then, the broker uses it to construct the key as <consumer_group_name>, <topic>, <partition> and value as <offset>,<partition_leader_epoch>,<metadata>,<timestamp> and store it in the __consumer_offsets topic.
When the consumer is crashed or restarted, it sends the request to the kafka broker and the broker finds the partition in __consumer_offsets by doing hash(<consumer_group_name>, <topic>, <partition> ) % 50 and fetches the latest offset and returns it to the consumer.
Disk I/O Optimization
Kafka uses the hard disk as its primary data store. We know that disk I/O is slow compared to the main memory. So, we may wonder how kafka is achieving low latency at high throughput. Let's dive into it.
Sequential disk reads can be faster than random memory access. Modern operating systems provide capabilities to read data from disk in multiple blocks.
Modern operating systems use free main memory for disk caching and divert disk I/O through this cache.
Relying on the disk cache is more optimal than the main memory because the disk cache stays warm even if the service had crashed or restarted.
Kafka uses index files for faster access. We discussed them above already.
Kafka batches disk writes.
Below is a sample log from the .log file. Let's dissect it.
baseOffset - the starting offset to start with
lastOffset - self-explanatory
count - the total number of messages in the batch
CreateTime - the epoch timestamp of created date
size - total size of the messages in the batch in bytes
baseOffset: 1992 lastOffset: 1995 count: 4 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 260309 CreateTime: 1672131859025 size: 474 magic: 2 compresscodec: none crc: 36982599 isvalid: true
| offset: 1992 CreateTime: 1672131859022 keySize: 12 valueSize: 84 sequence: -1 headerKeys: [] key: craigpearson payload: {"username": "craigpearson", "address": "0414 Fischer Rest\nZacharyshire, MN 38196"}
| offset: 1993 CreateTime: 1672131859024 keySize: 11 valueSize: 80 sequence: -1 headerKeys: [] key: gregoryjoel payload: {"username": "gregoryjoel", "address": "827 Nelson Burg\nSherrimouth, OK 49255"}
| offset: 1994 CreateTime: 1672131859025 keySize: 11 valueSize: 83 sequence: -1 headerKeys: [] key: gregoryjoel payload: {"username": "gregoryjoel", "address": "8306 Reed Trail\nFitzgeraldstad, PA 18715"}
| offset: 1995 CreateTime: 1672131859025 keySize: 12 valueSize: 84 sequence: -1 headerKeys: [] key: craigpearson payload: {"username": "craigpearson", "address": "0533 Crystal Forks\nJasminefort, NV 54576"}
Bonus
Offset Explorer - A useful tool to view topic and consumer information.


